In this step all geometrically connected regions are identified. Those
are determined for all points below a free energy threshold
\(\tilde{G}\). This is repeated consequently for all values threshold
specified with \(\mathtt{\mbox{-}T}\).
Execution
clustering density -f coordinate_file
-T from_fe step_fe [to_fe]
-r radius
-d/-D free_energy_file
-b/-B nearest_neighbor_file
-o output_basename
-n N
-v
Parameters
Input Parameters
Parameter
Description
\(\mathtt{\mbox{-}f :}\)
The name(path) of the input coordinates. The dimension
should not exceed 10.
\(\mathtt{\mbox{-}T :}\)
The screening of the free energy landscape. format: FROM
STEP TO; e.g.: \(\mathtt{\mbox{-}T\ 0.1\ 0.1\ 11.1}\). Set
\(\mathtt{\mbox{-}T\ \mbox{-}1}\) for default values: FROM
\(=0.1\), STEP \(=0.1\), TO \(=G_\text{max}\). If TO is not
given, e.g.: '\(\mathtt{\mbox{-}T\ 0.2\ 0.4}\)', than TO
\(=G_\text{max}\) to start at \(0.2\) and go
to \(G_\text{max}\) at steps of \(0.4\).
\(\mathtt{\mbox{-}r :}\)
The cluster radius \(R\) (same unit as input) used for
calculating the free energy and the nearest neighbor with
lower
energy. If this flag is not set the lumping radius
\(d_\text{lump}\)
will be used, so \(R=d_\text{lump}\). This will be ignored if
used
together with \(\mathtt{\mbox{-}D}\).
\(\mathtt{\mbox{-}D :}\)
Filename to read the free energies from. This should be used
with \(\mathtt{\mbox{-}B}\) and a nearest neighbor file
generated with the same cluster radius, otherwise use
\(\mathtt{\mbox{-}b}\). If used, \(\mathtt{\mbox{-}r}\) is
ignored.
\(\mathtt{\mbox{-}B :}\)
Filename to read the nearest neighbors from. This should be
used with \(\mathtt{\mbox{-}D}\) and a nearest neighbor file
generated with the same clustering radius, or together with
\(\mathtt{\mbox{-}r}\) and \(\mathtt{\mbox{-}d}\). This option
is ignored if \(\mathtt{\mbox{-}R}\) is set.
Output Parameters
Parameter
Description
\(\mathtt{\mbox{-}o}\)
This is the basename of the cluster output files. For each
free energy threshold a file with the found clusters is saved,
e.g. for \(\Delta \tilde{G}=2.6\) a file named
\(\mathtt{basename.2.60}\) is generated. \(0\) corresponds to
frames with a higher free energy than the current threshold
\(\Delta \tilde{G}\).
\(\mathtt{\mbox{-}p}\)
Filename for the output file of the populations for the
given radius. This option is ignored if not given together
with \(\mathtt{\mbox{-}d}\).
\(\mathtt{\mbox{-}d}\)
Filename for the output file of the free energies. The same
as \(\mathtt{\mbox{-}D}\), but generates the free energies for
the given radius.
\(\mathtt{\mbox{-}b}\)
Filename for the output file of the nearest neighbors. The
same as \(\mathtt{\mbox{-}B}\), but the nearest neighbors get
generated for the given radius.
Miscellaneous Parameters
Parameter
Description
\(\mathtt{\mbox{-}n}\)
The number of parallel threads to use (for SMP machines).
This is ignored if CUDA is used.
\(\mathtt{\mbox{-}v}\)
Verbose mode with some output.
Detailed Description
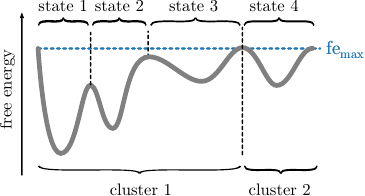
Before we explain the procedure, we want to note here that
clusters do not correspond to states. Clusters just separate the
space into geometrically connected regions. Those are per
construction separated at the highest available free energy, while
states are separated at all barriers. Therefore, gathers the major
cluster normally up to \(90\%\) of the total population.
Given the readily computed free energies (\(\mathtt{\mbox{-}d}\))
and neighborhoods (\(\mathtt{\mbox{-}b}\)) per frame for the
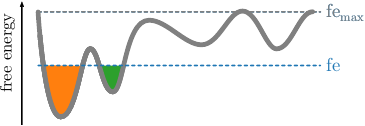
selected radius, we continue the clustering by screening the free
energy landscape. This means, we choose a (initially low) free
energy cutoff \(\tilde{G}\), select all frames below and combine
them into clusters, if they are geometrically connected with
respect to the lumping distance \(d_\text{lump}=2\sigma\), which
is automatically computed for the given data set. \(\sigma\)
denotes here the standard deviation of the nearest neighbor
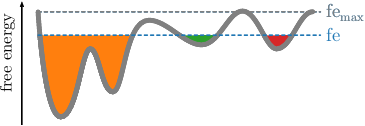
distances. An illustration is provided in the following figures.
If the threshold raises previous clusters can be merged.
This is done repeatedly, with increasing free energy cutoffs. The
end result will be multiple plain-text files, one for each cutoff,
that define cluster trajectories. Their format is a single column
of integers, which act as a membership id of the given frame
(identified by the row number) to a certain cluster. For each
file, the microstate ids start with the value 1 and are numbered
incrementally. All frames above the given free energy threshold
are denoted by \(0\), which acts as a kind of melting pot for
frames with unknown affiliation.
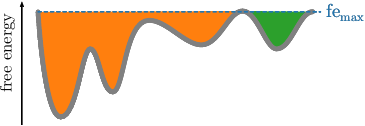
Do not worry if there are still frames denoted by \(0\) in the
cluster file of highest free energy. The clustering program
rounds the maximum free energy to 2 decimal places for screening,
which may result in a cutoff that is slightly lower than the true
maximum. Thus there may be frames left, which are not assigned to
a cluster since they are not below the cutoff.
However, since we are going to generate states from selecting the
basins of the clusters and 'filling up' the free energy landscape
from bottom to top, these states are not interesting on their own,
anyhow, and will be assigned to a distinct state in the next step.